股票杠杆
杠杆炒股,股票融资!

杠杆炒股,股票融资!
作家 | 移动云 kafka 团队李鸿鹏
背 景
本文记载了一个在海量日记检索 ELK 场景中,Filebeat 集聚日记写入到 Kafka 情势,Kafka 磁盘读写非常激勉的故障。其中 Kafka 集群内每个 Broker 节点都劝诱了两个 log 目次,每个目次单独挂载一块盘,当单块磁盘读写非常时,Filebeat 出现了写入 Kafka 抓续失败的问题。对 Kafka 来说,早有 KIP-112: Handle disk failure for JBOD 科罚访佛的问题,但为什么还会出现写入失败呢,接下来咱们将对问题原因进行长远领悟。
处理过程和表象
底下永别从客户端和工作端角度确认一下其时的表象。
客户端:音书写入失败,抓续有如下报错

工作端:网卡入流量从 40% 飙升到真是打满,何况该 Broker 节点出现了 offline 的 replica Broker 日记里有如下 IO 非常
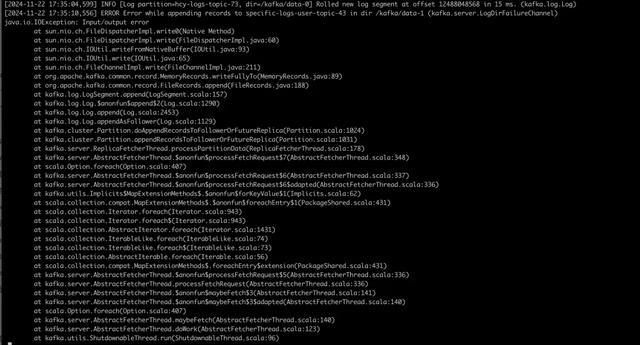
凭证以上表象判断是 Broker 节点 /kafka/data-1 目次挂载的磁盘故障激勉的问题,因为每个 Broker 节点劝诱了两个 log 目次,每个目次挂载一块盘,是以其中一块盘故障,Broker 节点进度并不会退出,但并不祥情为什么音书会写入失败。
意象 1:Broker 是否对位于故障磁盘目次的分区作念了正确处理?通过 Kafka-topics.sh --describe 发现,这些分区也曾完成了 leader 切换和 isr 剔除,从工作端角度看一切经常。
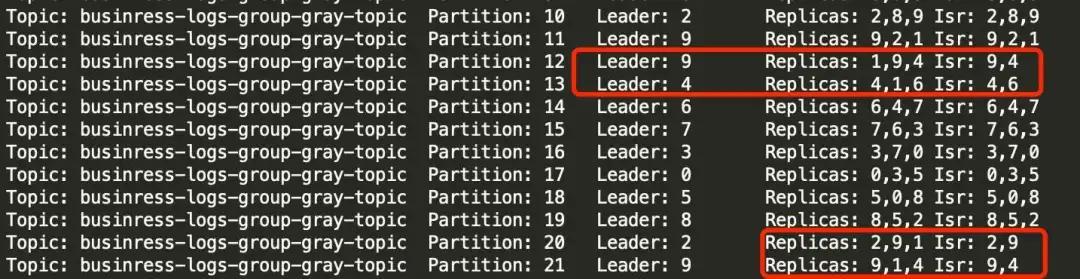
意象 2:是不是和这个节点网卡入流量打满关联?
合计 Broker 会去其它副本同步因磁盘故障丢失的数据,从而影响了业务写入,琢磨到主题每个分区都有三副本,通过关闭 Broker 节点进度的方式,停掉副本间同步的流量,随后业务音书写入复原经常。
天然业务临时复原了,但咱们还有好多疑问莫得获取解答,底下将对以下问题进行长远分析
Kafka 工作端在挂载多块盘的场景中,其中单块盘故障的处理历程是怎样样的?
磁盘故障节点的网卡入流量打满到底和副本同步流量有没关筹谋?
本次问题的压根原因是什么?
分析过程
在进行问题分析前,有必要先了解一下问题发生的场景,因为问题一般只在某种特定的场景下发生,是以这部分相当遑急。
问题发生场景
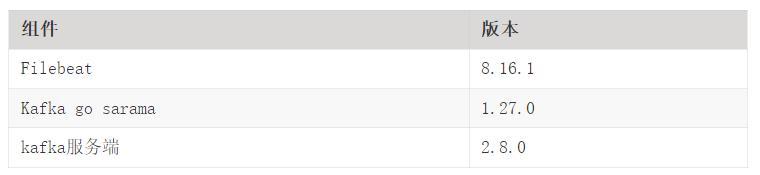
各组件版块信息如下表所示:
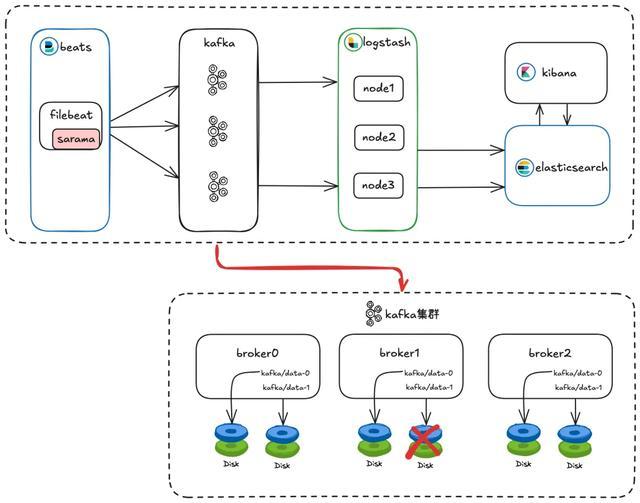
另外还需要把稳的是,Kafka 集群的每个 Broker 节点设立两个 log 目次,每个目次挂载一块单独的磁盘,本次是某个 Broker 节点的其中一个目次挂载的磁盘发生了读写非常。
问题分析
Kafka 工作端在挂载多块盘的场景中,其中单块盘故障的处理历程是怎样样的?
Broker 运转时检测到 log 目次读写非常
散布在读写非常 log 目次下的副本引申和收到 StopReplicaRequest 相通的操作,充任 leader 变装的副本不再被视为 leader,充任 follower 变装的副本罢手从其 leader 副本同步音书,Broker 同期会把我方内存里的副本情状标志成 Offline。
Broker 奉告 Controller 节点我方发生了 LogDirFailure 事件
Controller 收到奉告,发送 LeaderAndIsrRequest 申请查询这个 Broker 节点悉数副本的情状,位于读写非常 log 目次下的副本将复返特定 KAFKA_STORAGE_ErrOR 情状码
Controller 把复返 KAFKA_STORAGE_ERROR 情状码的副本标志成离线,触发分区 leader 再行选举
Controller 把离线的副本从 isr 里移除,何况给联系的 Broker 发送 LeaderAndIsrRequest 申请,告诉他们 isr 变化
Controller 在集群内播送最新的 metadata 信息
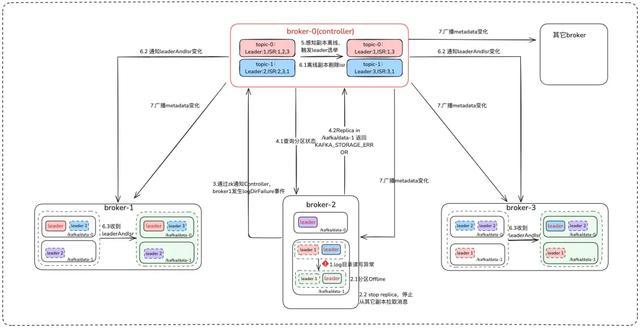
讲求:通过以上分析可知,Kafka 工作端能实时将散布在故障磁盘目次的分区 leader 切换到其它副本,保证高可用。
磁盘故障节点的网卡入流量打满到底和副本同步流量有没关筹谋?
不首要,通过以上对 Kafka 故障升沉完竣旨趣的分析,磁盘故障节点并不会从其它节点同步音书,而且通过不雅察其它 Broker 节点的网卡出流量并莫得较着变化也印证了这少量,确认咱们其时意象是失实的。
本次问题的压根原因是什么
通干豫题一的分析也曾排斥了 Kafka 工作端的问题,外汇配资接下来从客户端角度进行分析。当先咱们对磁盘故障场景进行了复现,故障触发后 Filebeat 抓续有如下报错直到 Broker 磁盘复原,这个信息相当环节,确认 Filebeat 照旧抓续往磁盘故障的节点写入音书,这也恰是 Broker 节点网卡入流量飙高的原因,针对这些写入申请,Broker 复返了 KafkaStorageException 的失实码。
怀疑是 Filebeat 所使用的 Kafka go sarama 客户端莫得感知到分区 leader 的切换导致的,在从 go sarama 客户端角度分析为什么莫得感知到之前,咱们需要先望望 Broker 单块磁盘故障后,在工作端也曾完因素区 leader 切换的情况下,客户端写入申请它是如哪里理的,会给客户端复返什么样的失实,为什么是 KafkaStorageException 而不是 NotLeaderForPartitionException。


通过分析源码发现,Broker 处理分娩申请时会先查验分区副本的情状,若是是 offline 情状的话就平直抛 KafkaStorageException 非常了,是以不会复返 NotLeaderForPartitionException。
当今再行回到 Kafka go sarama 客户端角度,sarama 在以下两种场景会从 Broker 引申拉取 metadata 更新分区 leader 的操作。
和 Broker 邻接关闭
音书写入收到 ErrNotLeaderForPartition、ErrUnknownTopicOrPartition、ErrKafkaStorageException 等失实码,不外 ErrKafkaStorageException 是 2024/8/8 才加入进去的,在 sarama1.43.3 之前的版块,是不包含对这个失实码的处理的。
是以怀疑的重心便是使用的 sarama 版块不包含对 ErrKafkaStorageException 的处理,为了考据这个猜念念,咱们对 sarama 1.43.3 及之前的版天职别进行了考据。
sarama 1.43.3 发达合乎预期,经常的感知到了分区 leader 的变化。
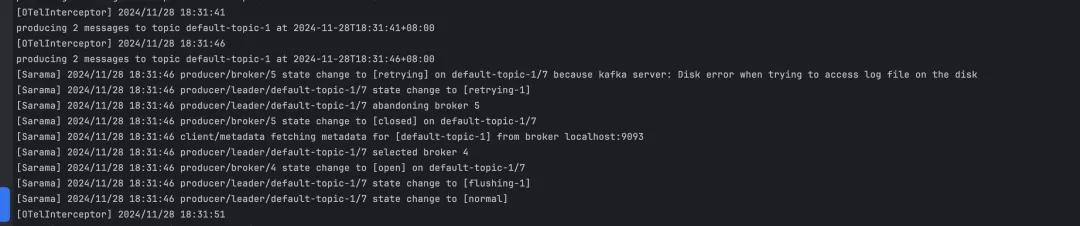
低于 1.43.3 之前,中式 Filebeat 最新版块 8.16.1 使用的 sarama1.27.0 版块,当磁盘故障后,它的分区的 leader 莫得更新,发送音书会抓续报错。
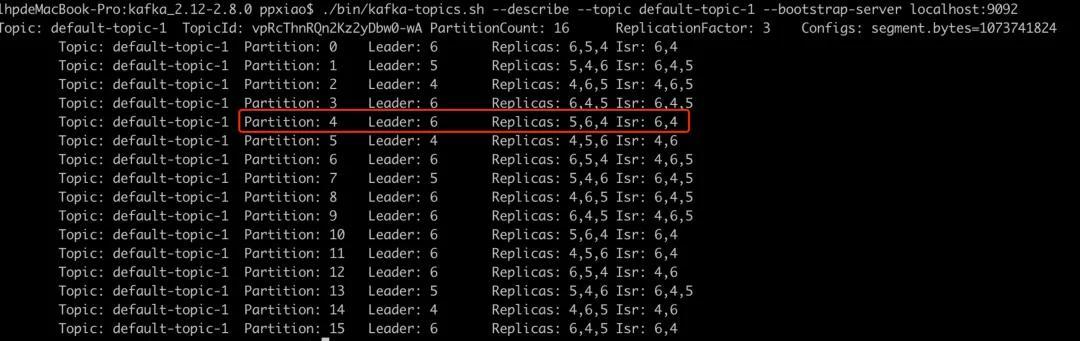
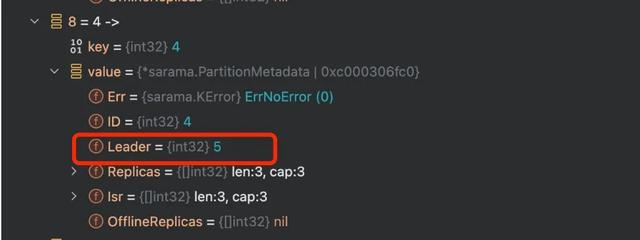
另外,和 Kafka 原生的 java 客户端对比,KafkaStorageException 是 InvalidMetadataException 的子类,收到这个失实码会更新 metadata,另外 Kafka java 的客户端还有如期更新 metadata 的机制,在 sarama 莫得看到访佛的完竣,可见 sarama 的更新 metadata 机制并不完善。
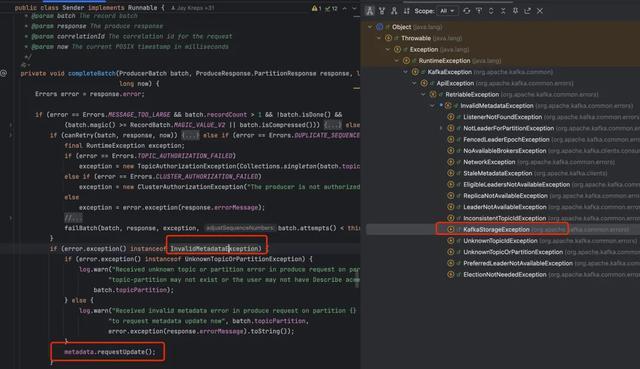
讲求:在 Broker 节点劝诱多个 log 目次,每个目次挂载一块单独的磁盘的场景,若其中一块盘发生故障,低于 1.43.3 版块的 sarama go 客户端莫得对 Broker 复返的 ErrKafkaStorageException 失实码进行正确处理,导致一直感知不到分区 leader 的变化,是以音书写入抓续失败。
科罚措施
临时科罚措施:重启 Filebeat 或重启磁盘非常的 Broker 节点,触发客户端拉取 metadata 感知分区 leader 变化。
弥远科罚措施:咫尺 Filebeat 最新版块 8.16.1 使用的 sarama 版块仍莫得科罚这个问题,只可通过单独升级 sarama 到 1.43.3 版块或等 Filebeat 更新 sarama 版块科罚。
结 论
Kafka Broker 着实对上述磁盘故障场景作念了很好的撑抓,问题原因是 Filebeat 所使用的 Kafka go sarama 客户端更新 metadata 的机制不完善,莫得和 Kafka 原生 java 客户端对皆。Kafka Broker 不错实时的感知非常并进行分区 leader 的切换,但 Kafka go sarama 客户端无法感知到,仍旧往分区蓝本的分区 leader 发送音书,毫无疑问会发送失败,也就导致了本次问题。