股票杠杆
杠杆炒股,股票融资!

杠杆炒股,股票融资!
文 | 竞合东说念主工智能
距离国产大模子作念考研数学题“过线”刚过两个月,月之暗面在春节前一周,又扔出了一个重量所有的“王炸”——这一次,他们拿出了能比好意思Open AI 满血版 o1(Full Version,而非 preview)的K1.5多模态模子,在笔墨和视觉两大限制竣事了“超英赶好意思”。
Kimi官方刚一发布,X网友的反应速率比假想中要快许多。无论是近在咫尺的日本、大洋此岸的好意思国,以致富得流油的阿拉伯,他们无不惊艳于Kimi模子推理能力的进展,以及多模态能力的栽种。
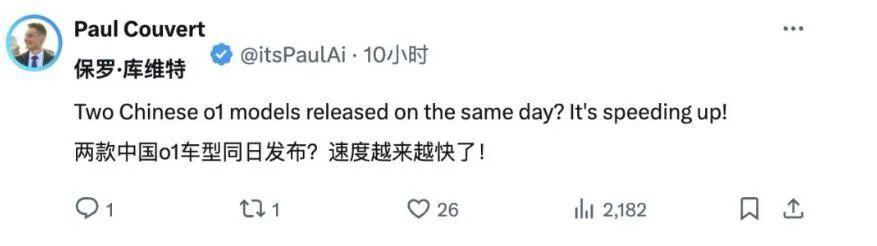
这些爱慕,是对中国AI奇迹进展最佳的饱读舞。
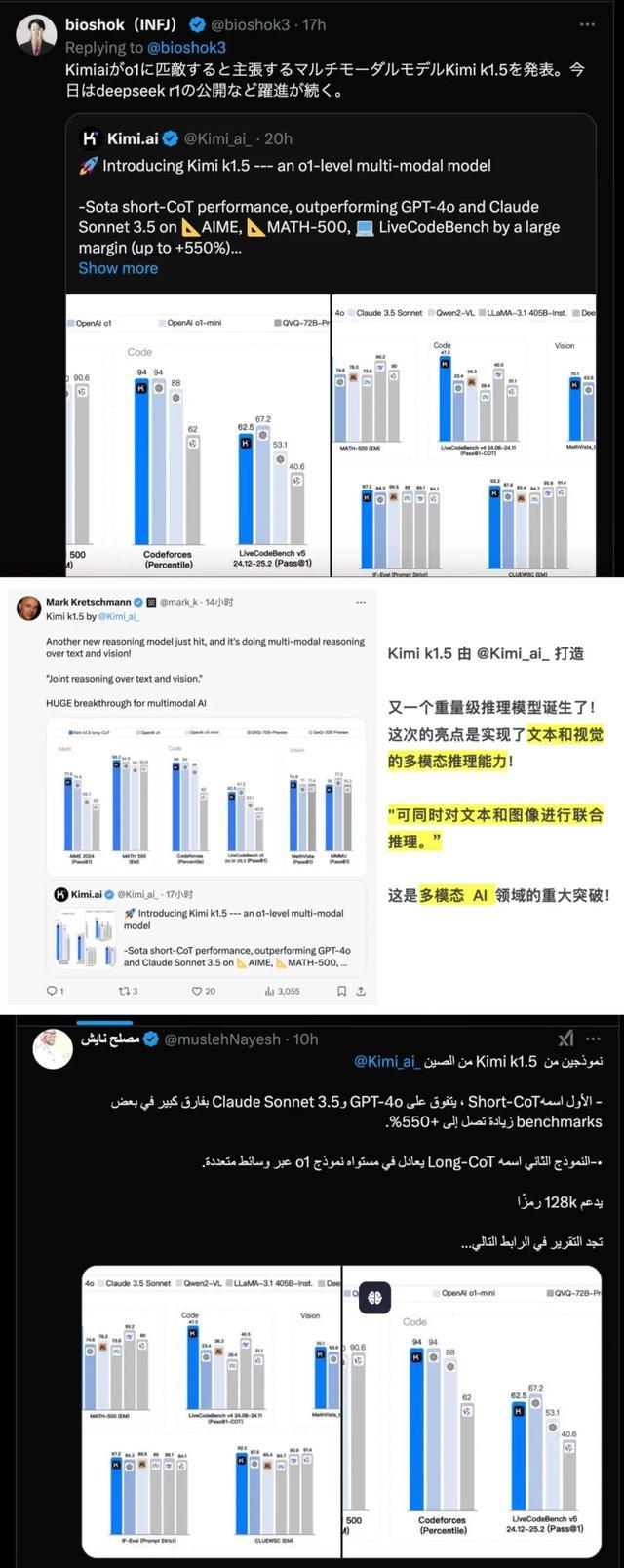
再看发布时刻,DeepSeek-R1的上架时刻还要略早一些。但就模态各样性来看,K1.5是当今OpenAI以外,独逐一个竣事o1郑再版多模态推理的大模子。其含金量不言而谕。
在更径直的性能竣事方面,kimi k1.5的测试呈报解析,在short-CoT 模式下,k1.5依然大幅独特了大家领域内短想考 SOTA 模子 GPT-4o 和 Claude 3.5 Sonnet 的水平,跳跃度达到 550%;
long-CoT 模式下,Kimi k1.5 的数学、代码、多模态推理能力,与当今第一梯队的OpenAI o1 满血版比拟,也不遑多让。
相较以往的闭源,Kimi还初次发布了历练呈报《Kimi k1.5:借助大谈话模子竣事强化学习的 Scaling》。
从Chatgpt横空出世于今,中国AI厂商大多数时刻里都在摸着OpenAI的石头过河。但从K1.5等国产大模子启动,咱们大可发现,以往以泰西为中心的AI行业全国线。依然悄然发生变动。
01 中国AI厂商的“源神”时刻
近三个月,毫无疑问是月之暗面工夫效用的采集获利期。
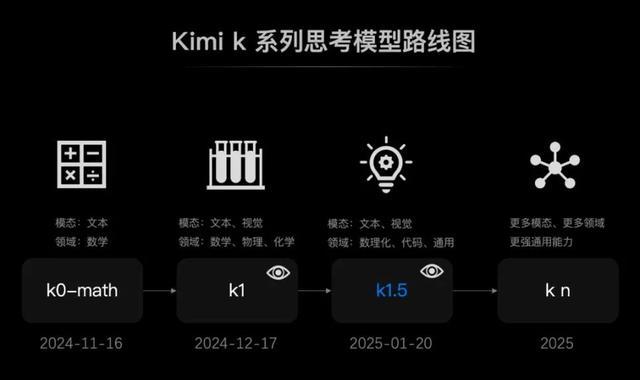
前年11月,月之暗面发布了k0-math 数学模子、12月发布 k1 视觉想考模子,这是第三个月在K系列强化学习模子的重磅升级。
比拟国内厂商和用户的“欢悦”,国外,尤其是硅谷专科东说念主士的主张梗概更能径直阐发问题。
当先是OpenAI等一线厂商,在AGI探索方面渐渐停滞。靠近外界坏话,OpenAI的CEO奥特曼径直发推辟谣,否定依然竣事了AGI通用东说念主工智能。同期下个月也不会部署AGI。关于宽敞从业者和联系厂商而言,既是预期上的打击,雷同也给了家具追逐的契机。
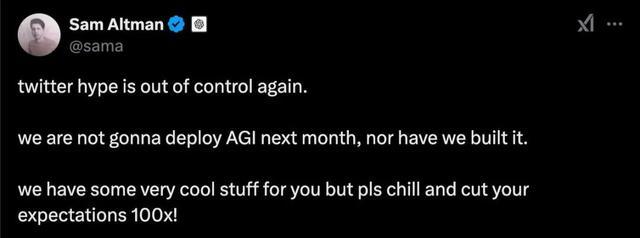
与之造成对比的,则是靠近月之暗面和Deepseek的最新推理模子效用,宽敞国外AI大V对此则相当振奋。英伟达大佬Jim Fan当即发推爱慕说,现货黄金投资R1不啻是通达了模子,工夫的分享也尽头紧要。
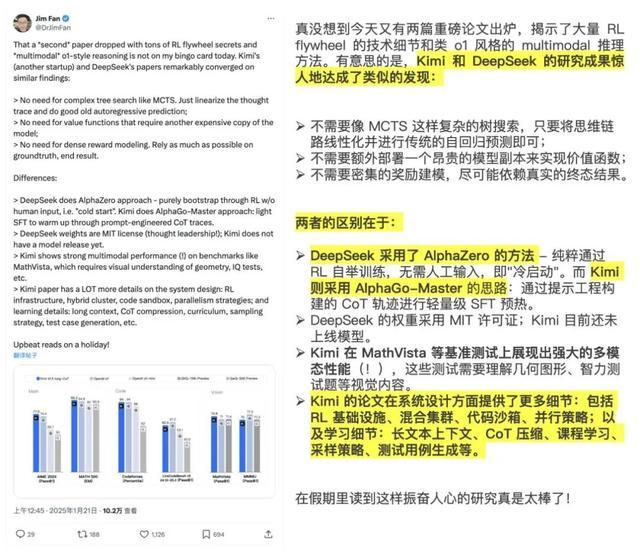
凭证他的对比,固然Kimi和DeepSeek的论文的要点都在比较访佛的发现,比如:
不需要像 MCTS 那样复杂的树搜索。只需将想维轨迹线性化,然后进行传统的自记忆议论即可;
不需要另一个腾贵的模子副本的价值函数;
无需密集奖励建模。尽可能依坏事实和最终规章。
但二者仍然有比较彰着的各异。如:
DeepSeek 采选AlphaZero 花式 - 纯正通过 RL 指令,无需东说念主工输入,即“冷启动”。
Kimi 采选 AlphaGo-Master 花式:通过即时绸缪的 CoT 追踪进行轻度 SFT 预热。
绝不夸张地说,起码在短链想维链,也即是短模子限制,K1.5地跳跃度是断崖式的,依然很猛经由独特了大家领域内短想考 SOTA 模子 GPT-4o 和 Claude 3.5 Sonnet 的水平,跳跃达到 550%。
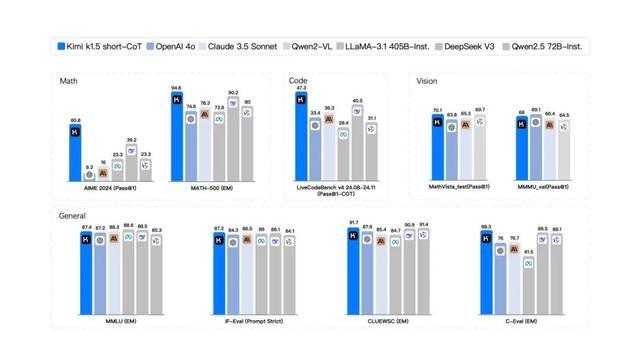
不错看到,除了多模态的视觉能力稍有弱项,其他方面的确与OpenAI处于归拢梯队以致浑沌压过一头,对其他国产友商依然彰着拉开了差距。
此外,要是从大家前沿大模子数学竞赛和编程竞赛基准测试来看,K1.5延续了此前K0-math的优异性能,处于大家第一梯队。
02 K1.5的工夫冲破之路
值得一提的是,股票配资平台哪个好以往月之暗面的工夫发布,都所以闭源家具的花式,本次K1.5,破天瘠土将工夫呈报和历练细节也一并放出(地址:https://github.com/MoonshotAI/kimi-k1.5)。
在月之暗面看来,“AGI 之旅才刚刚启动。咱们想让更多工夫东说念主才了解咱们在作念的事情,加入咱们沿途作念到更多。”
透过这份工夫力拉满的呈报,咱们不错一窥国产厂商在推理模子限制,若何竣事对国际大厂的赶超。
从当今放出的呈报来看,最大的工夫亮点之一,无疑是“Long2Short”历练决议。
这里波及到两个要津理念,长凹凸文 scaling 和蜕变的政策优化。
具体而言,他们先愚弄最大可膨大到128K的凹凸文窗口,使得模子学会长链条想维。同期使用 partial rollout——即通过重用无数以前的轨迹来采样新的轨迹,幸免从新再行生成新轨迹的本钱,以此提高历练效用。
有基于此,他们将蓝本“长模子”的效用和参数,与小而高效的“短模子”进行合并,再针对短模子进行异常的强化学习微调。
这么作念的根由是,尽管长链推理(long-CoT)模子推崇优异,但在测试时挥霍的记号数目比圭臬短链推理(short-CoT)大模子更多。
同期,他们推导出了一个具有 long-CoT 的强化学习公式,并采选在线镜像下落法的变体来竣事矜重的政策优化。通过有用的采样政策、长度处分和数据配方的优化,他们进一步蜕变了该算法。
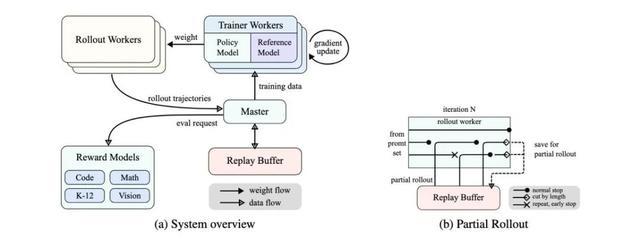
此外,他们还用到了诸如最短拒却采样和DPO等状貌,以在有限的测试token预算下,最猛经由栽种模子性能。
谋划者不雅察到,模子在恢复换取问题时生成的反应长度存在较大各异。基于此,他们绸缪了最短拒却采样(Shortest Rejection Sampling)花式。该花式对归拢个问题采样 n 次(实践中,n=8),并采用最短的正确反应进行监督微调。
DPO与最短拒却采样访佛,团队东说念主员愚弄 Long CoT 模子生成多个反应样本。并采用最短的正确惩办决议算作正样本,而较长的反应则被视为负样本,包括失实的较长反应和正确的较长反应。这些正负样本对组成了用于 DPO 历练的成对偏好数据。
以当今的这套决议,不错在最大化保留长模子推理能力的前提下,有用开释短模子的高效推理和部署上风,躲闪长模子“精简模子后能力松开”的问题。
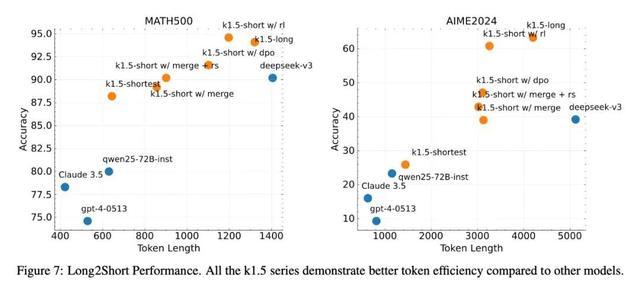
测试也能标明,使用“Long2Short”历练决议之后,K1.5历练模子的效用栽种十分彰着。(越靠右上效用越高)。
03 结语
回望想考模子的工夫道路,最早涉足该限制的OpenAI,辩认在前年9月、5月推出了GPT-4o、o1。它们辩认代表了多模态剖释和强化学习两个不同道路。
对比往日两年,国内厂商发力追逐的速率依然坂上走丸,Kimi的自后居上依然填塞阐发一些问题,在一些细分限制,中国AI如今依然追平了与国外的差距,站在归拢条起跑线上,其后的发展,界说权梗概依然不在OpenAI手中。
短短一个季度,Kimi就从单纯的“会算”变成了“会看”,并在以肉眼可见的速率集都多模态,且浑沌有成为长板的趋势。
据月之暗面官微信息,2025 年,Kimi 会接续沿着道路图,加快升级 k 系列强化学习模子,带来更多模态、更多限制的能力和更强的通用能力。
让咱们翘首企足。